

Today we are going to create a dynamic, zero-touch, PR (Pull Request) environment, a place for us to validate and test our enhancements. Ultimately, this will help give us more confidence that changes merged into the main branch will be of the highest quality.
In the past, the cost, time, and effort required to setup this temporary environment was prohibitive. Most projects we’ve worked on require at least a web server and database server as a minimum. With setup times of VMs averaging several weeks and approvals, it has traditionally been difficult to setup an environment quickly.
With the Azure cloud, and PaaS, it’s finally attainable, as we can easily automatically create and tear down environments in minutes. It’s also affordable. For roughly ~$60 a month, we have a full environment with a SQL database, web servers with staging slots, application insights, a storage account, Redis, and a CDN. As most branches are short-lived, surviving a few hours or days, this cost is a fraction of the total, a few dollars a day.
Our workflow today
In our project to date, we’ve been primarily working with three environments:
- “Dev” or Development: where we actually build and develop our new features. As part of the build that runs in a pull request, we deploy our changes to Dev to validate the PR won’t break our deployment
- “QA” or Quality Assurance: Only runs on the main branch, after a successful build and deployment to Dev.
- This environment is meant to be identical to Prod from a vertical scale (same CPU/memory/storage), but with a lower horizontal scale, (VM instances running PaaS in the back end).
- This is also where we can safely run our load and performance tests, knowing it’s similar to Prod.
- “Prod” or Production: The last step in our process, after QA is deployed, where our end users engage with our product.
What happens when our team scales to 10 or 100 developers? Our current setup works until two or more developers start pull request builds at the same time, stomping on each others changes in development. What is the solution? We need a separate environment for each pull request, giving our developers a place to work and test.
The new workflow
- The developer takes work off the Kanban board, creates a branch, and does “the work”
- The developer commits and pushes this branch, creating a new pull request. This triggers a PR build, and a new pull request deployment. For example, if the pull request is #415, a resource group is created “SamLearnsAzurePR415, and all of the resources are named with PR415, and the DNS to the website is setup as pr415.samlearnsazure.com.
- When the pull request is complete, a web hook monitors changes, and runs some code to delete the resource group.
Updating the YAML pipeline
Our first step is to add a new PR stage to our YAML pipeline. We can see the new stage, as well as the rules surrounding it, highlighted in red below and in our repo. There is a significant amount of trial and error hidden by these 12 lines. Achieving a build that works in a PR build and main branch build was a challenge.

Let us walk through this workflow in more detail, reviewing the 5 stages:
- Build: Runs as before, no changes
- DeployPR: Runs if build stage was successful, the “Build reason” equals “PullRequest”, and the “Pull Request Id” variable is not null.
- Three variables are set to help create a PR environment. In our other environments we use “Dev”, “QA”, or “Prod” to describe the environment. For PR environments, we will be using the format “PR###”. For example, if the PR Id is 429, a resource group “SamLearnsAzurePR429” will be created, with all of the resources needed to run an environment.
- To make the variables work, we used “conditional insertion” expressions, that load in a value depending on the current source branch. Note that when the branch is main, and the PR variable is set to ‘000’, the actual stage is still skipped. We found we needed to set this variable (to ‘000’) to ensure the YAML processing doesn’t throw errors.
- DeployDev, DeployQA, and DeployProd: Runs in serial, if the build stage was successful, and the source branch being run equals “master” – essentially it’s not a pull request.
Here is a Pull Request with this new process, note the PR ID of “429” in the top left, which will be used to build our “PR429” environment.

Looking at the pipeline process, we can see the build runs as expected, and as we are running a PR build, only the “Deploy PR” stage is triggered. Note that while the first run to create our infrastructure takes 35 minutes, subsequent runs finish in ~10 minutes. This extra time is related to one off tasks to provision the Azure resources, and restore the SQL database.

With the build policy completed, we can browse to pr429.samlearnsazure.com, a sub domain created as part of the deployment, and see the website loads with data present. This confirms the DNS was configured, and we were able to restore data into the database successfully.

This included dynamic creation of a CNAME DNS record for “pr429”, using the GoDaddy API (as our DNS is hosted by GoDaddy). This creates a friendly version of our site to browse to, (pr429.samlearnsazure.com), instead of having to remember the actual resource name.

In the Azure Portal, we can see our new resource group “SamLearnsAzurePR429”.
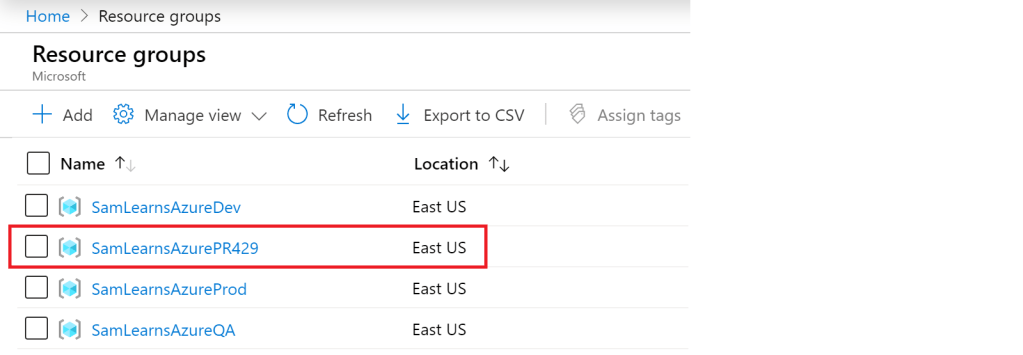
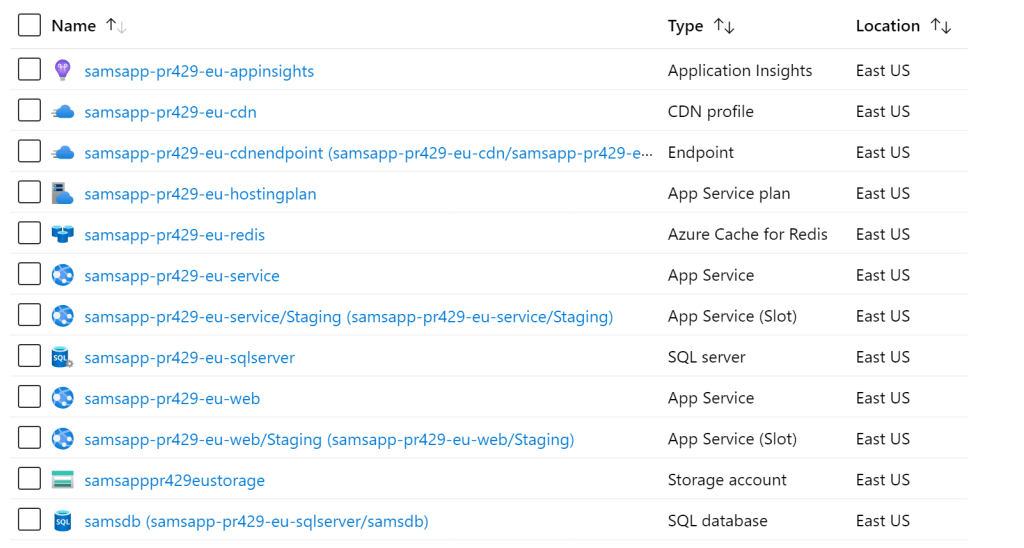
Examining the contents of the resource group, we can see all of the unique resources that make up an environment, all with the “pr429” naming.
What happens to these resources when the Pull Request is completed?
Once a Pull Request has been completed, our build will run it’s regular CI/CD workflow, running all stages except the “Deploy PR” stage.

With the resources in our pull request environment now unneeded, we can tear down this environment – after all, we are paying for it. To achieve this, we use a webhook in Azure DevOps to extend and watch the pull request for updates. When the pull request status changes to “completed”, the web hook logs into Azure and deletes the resource group for us. Here is a screenshot of the service hooks history. The failures in the screenshot represent timeouts we will address in a future post.

Note that the runtime environment name doesn’t ever resolve – I suppose this is a bug in Azure DevOps that needs to be resolved:

Wrap-up
We have created an automated process to create an isolated development environment to test our development with pull requests. This is an incredible achievement for this project, a feature we had been planning for months. We plan to look into closer into some of the details we’ve glossed over today in the next few weeks, including:
- Creating the Webhook to extend our pull requests and delete the PR resource group when the PR is complete. (blog post) (code)
- Creating a PowerShell script to create Go-Daddy CNAMES (blog post) (code)
- Adding a database restore step during the PR creation if the tables haven’t been populated (our PR environment needs data to test!) (code)
As we complete these future posts, we will link to them here to keep the series together.
References
- Using null in conditions: https://stackoverflow.com/questions/56875665/how-to-deal-with-null-for-custom-condition-in-azure-pipeline
- Passing variables between stages: https://stefanstranger.github.io/2019/06/26/PassingVariablesfromStagetoStage/
- YAML Variables: https://docs.microsoft.com/en-us/azure/devops/pipelines/process/variables?view=azure-devops&tabs=yaml%2Cbatch
- YAML Expressions: https://docs.microsoft.com/en-us/azure/devops/pipelines/process/expressions?view=azure-devops#functions

Hi Sam,
Just curious are you defining your build steps in your build pipeline or is the build stage included in your release pipeline?
LikeLike
Good question – it’s a bit of both, it’s a multi-stage pipeline, which is both a build and release. More details in an old blog post here: https://samlearnsazure.blog/2019/05/24/learning-about-multi-stage-yaml-pipelines/
LikeLike
Thanks! We’re currently running Azure Devops Server in our organization and it doesn’t look like this feature is available yet for this version but I’ll keep an out.
LikeLike
Correct, but it’s scheduled in an update for this quarter!
See “General availability of multi-stage pipelines UX” on the roadmap, about 9-10 lines down: https://docs.microsoft.com/en-us/azure/devops/release-notes/features-timeline
LikeLike
Hi Sam,
Great to see you could use one of blog posts as reference. Keep up the great work!
Stefan Stranger
LikeLike
Very helpful Stefan – the whole variables story is a bit grey, and you helped make it black and white. Thank you!
LikeLike
Hi Sam,
This is a very interesting post. We’re doing something very similar ourselves but have found your walkthrough very useful in allowing us to take our pipeline to the next level. Particularly the harnessing of templates and the new deployment and environment capabilities.
On environments (names), have you found that the dynamic PR specific environment names do not resolve properly? I’ve tried a few combinations but it looks like runtime resolution of the environment name isn’t currently supported perhaps?
For example, in the pipeline.yml you’d have something like as follows (my defaultPoolName is defined as a global variable):
– stage: Deploy_PR
variables:
prId: $(System.PullRequest.PullRequestId)
…
deploymentEnvironment: “Orca-PR$[variables.prId]”
jobs:
– template: pipeline-deploy-azure-template.yml
parameters:
Pool_Name: “$(defaultPoolName)”
Environment_Name: “$(deploymentEnvironment)”
And in pipeline-deploy-azure-template.yml you’d define something like:
parameters:
Environment_Name: “”
Pool_Name: “”
jobs:
– deployment: Deploy_Azure
displayName: Deploy infrastructure to Azure
environment: ${{parameters.Environment_Name}}
pool:
name: ${{parameters.Pool_Name}}
The pool name resolves no problem, however the environment name resolves to $(deploymentEnvironment) when viewing the environment tab on the details of the pipeline run. From your screenshot it looks like you may have the same issue looking at your job names under your Deploy PR Stage stage.
LikeLike
Hi Justin, you are correct. Unfortunately the environment names don’t resolve. Here is my current environments page: https://samlearnsazure.files.wordpress.com/2020/05/21environments.png.
It was just cosmetic to me, and since I don’t have approvals on my PR environments, or honestly even look at this page much, I barely notice it.
Please keep me updated on where you end up, I’d love to see the end result and hear about any changes you made to improve or adapt it to your situation!
LikeLike
Hi, firstly great article!
I have one question. How would you create a dynamic PR environment if a team has 2 repos (one for backend and one for frontend) and the team would like to have dynamic environment per UserStory?
LikeLike
Thanks!
As for your question, you have (at least) two options, the first is my favorite.
1. the back end and front end are in different repos because they are separate pieces of code – and therefore should be developed and tested independently. Similar to a microservice, all of your development and testing is independent of other products.
2. Alternatively because you are managing two repos, you can’t use a single PR. You could potentially use the User story number to name an environment instead of a PR – you’d just to have to think about how to merge two branches together to deploy to a common environment.
LikeLike
Thanks. Helpful article, but please could you assist with further clarification, if the following is possible…
When a PR is raised, and successful (eg: source branch = feature/* gets merged into target branch = master), and the source branch is then deleted. How can one initiate a pipeline automatically based on the above conditions to perform an environment cleanup?
I’ve tried using this condition, but this is only valid when using Build Policies (which are no good, since they run before PR is completed):
condition: and(succeeded(), in(variables[‘Build.Reason’], ‘IndividualCI’), in(variables[‘Build.SourceBranchName’], ‘boss-branch’), in(variables[‘System.PullRequest.SourceBranch’], ‘refs/heads/feature/*’))
Would you recommend a separate pipeline running on a schedule? Or how can I link it to run only when PR is completed.
Your assistance is appreciated
Regards
LikeLike
I used a webhook to clean up environments: https://samlearnsazure.blog/2020/03/03/creating-a-webhook-to-extend-our-pull-requests/
LikeLike
Thanks. yeah I read that article before I got here, but sadly the Azure DevOps UI Service Hook section doesn’t allow for much customisation, so cannot specify source branch during the PR. You can only invoke the webhook if a PR is updated against ‘master’.
I wouldn’t want to initiate an environment cleanup based on every successful PR to master, but only when coming from specific branch/es (and when that source branch is deleted as well during PR)
LikeLike
Thanks. Helpful article, but please could you assist with further clarification, if the following is possible…
When a PR is raised, and successful (eg: source branch = feature/* gets merged into target branch = master), and the source branch is then deleted. How can one initiate a pipeline automatically based on the above conditions to perform an environment cleanup?
I’ve tried using this condition, but this is only valid when using Build Policies (which are no good, since they run before PR is completed):
condition: and(succeeded(), in(variables[‘Build.Reason’], ‘IndividualCI’), in(variables[‘Build.SourceBranchName’], ‘master’), in(variables[‘System.PullRequest.SourceBranch’], ‘refs/heads/feature/*’))
Would you recommend a separate pipeline running on a schedule? Or how can I link it to run only when PR is completed.
Your assistance is appreciated
Regards
LikeLike
What if you posted to a queue in Azure when you completed a branch, and then a function/webhook did work based on the branch in that queue?
LikeLike